在这次数据技术嘉年华大会上,我和大家分享的主题是Oracle的In Memory新特性。In Memory特性是Oracle12c推出的三个重大新特性之一,通过引入内存中独立的列存区域,可以大幅度提升查询性能。

这次的主题主要从四个方面展开,首先介绍In Memory的基础架构,Oracle采用什么的架构来支持In Memory内存区域的存储和查询访问。

在正式开始之前,首先把一些易混的概念梳理清楚,Oracle中有太多的内存缓存组件,简单介绍一下各自的功能和差异。DB Cache是数据块的缓存,日常的增删改查都需要先将数据保存到这个区域,而DB Cache又跟据使用差异的不同分为Default、Keep和Recycle三个区域,Cache是表的属性,可以控制读取表数据的时候放到LRU链表的位置;Result Cache是11g引入的功能,可以直接将SELECT的查询结果或FUNCTION的返回结果缓存下来,再次访问的时候,如果依赖的对象没有发生过修改,可以不再进行查询或调用,而是直接返回Result Cache中缓存的结果;Memoptimize功能是在18和19中分别针对非常频繁的读表和写表进行的优化,通过设置独立的内存区域来加速对应的访问;Timesten是Oracle的独立的内存数据库,用来针对超高速的OLTP的请求,其独立部署支撑的TPS最高记录已经突破1亿;最后登场的就是今天要介绍的重点Oracle Database InMemory选件。
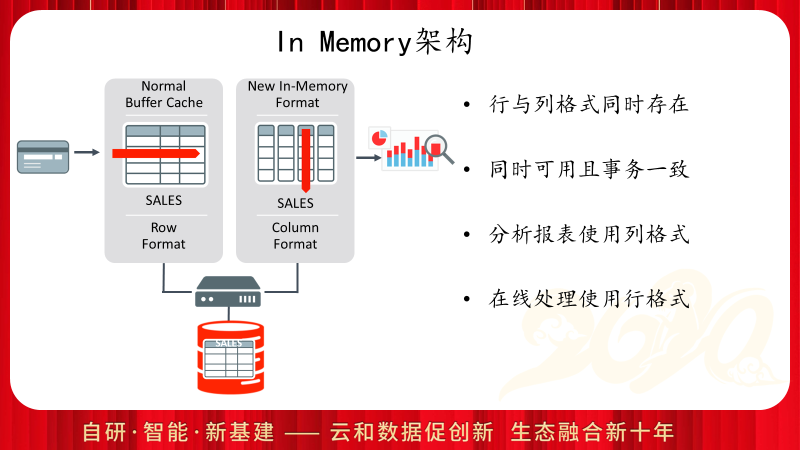
Oracle的In Memory功能并不是原有功能的替换,而是新功能的叠加,也就是说在保留DB Cache读写全部的功能的基础上增加了额外的列存区域。Oracle针对In Memory的访问同样提供了事务性,也就是针对列存区域的访问,ACID的功能同样是提供的。而且Oracle针对In Memory的使用已经彻底做到了CBO自动判断,证明这个功能已经相对成熟。
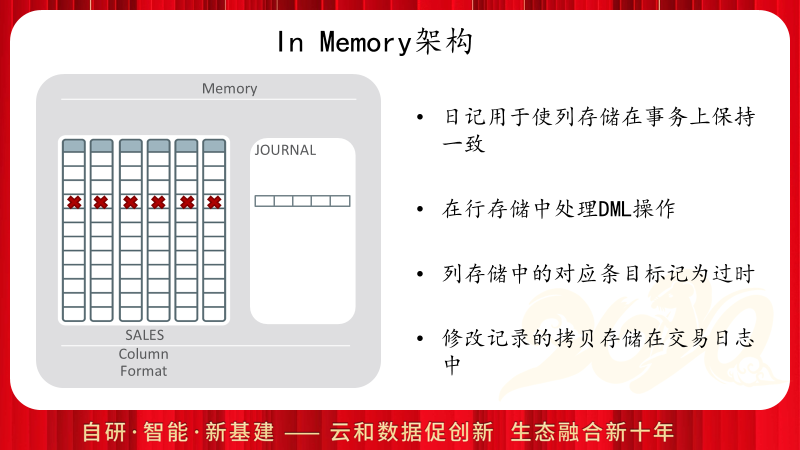
简单说明In Memory是如何提供事务一致性访问的,当DML修改DB Cache的数据块时,In Memory区域并不会同步修改,但是Oracle通过在对应行上打标记的方式通知In Memory,这里存在修改的数据,同时将DML的修改同步到In Memory的独立日志区。在查询访问时,访问In Memory区域之后,还需要访问日志区,将其中的DML修改Merge到列存读取的结果上,从而提供一致性的访问。
介绍完了In Memory的架构,下面来看看In Memory的性能优势和功能:
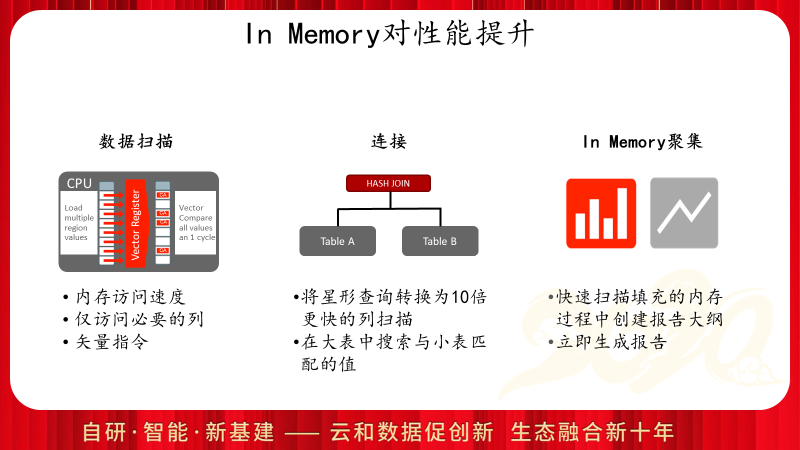
In Memory对于查询访问的提升主要来自三个方面,除了内存访问带来的数据扫描的性能提升外,还可以配合星形查询转换以及布隆过滤等大幅度提升表连接的性能,此外In Memory对于聚集操作也有明显的性能提升。

In Memory除了可以加速表中列的访问速度,对于虚拟列或表达式计算也可以进行加速,使用内存表达式加速有用户定义虚拟列或Oracle自动检测两种方式。

由于系统中内存的容量总是有限的,In Memory除了提供压缩算法来降低内存的使用外,还可以配合12c的新特性Heatmap和ILM来自动完成数据段在In Memory内存中的生命周期管理。
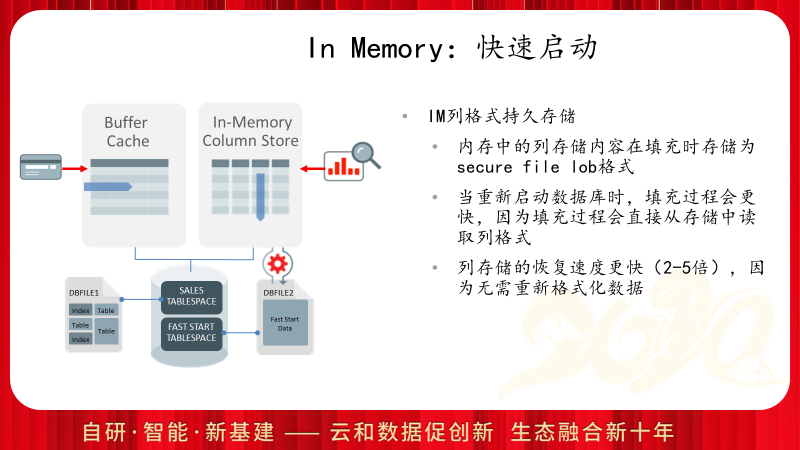
由于In Memory的数据来源与存储在数据文件中的行格式,因此重启过程中会需要读取大量的数据到内存区。Oracle提供了加速这个过程的功能,通过设置独立的In Memory快速启动表空间,使得Oracle把列存的数据直接保存在表空间中的SECURE FILE LOB对象中,从而加速In Memory的数据加载过程。
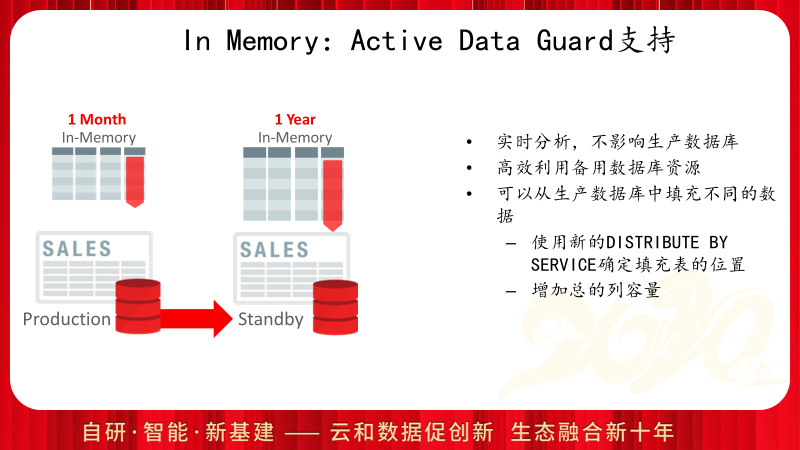
Oracle不仅仅持主库的In Memory功能,还可以通过DISTRIBUTE BY SERVICE提供在DG库上的In Memory访问功能,这样可以更加充分的发挥DG的报表功能并提供报表系统内存横向扩展能力的。

In Memory带来的最大好处莫过于性能提升,只需要配置内存区间,并加载表数据到内存区域中,就可以实现查询性能的几倍到上百倍的提升。而且In Memory的设置对应用透明,不需要任何代码的修改,就可以实现性能的提升。

既然In Memory的性能优势如此突出,下面看一下In Memory的使用场景和最佳实践。
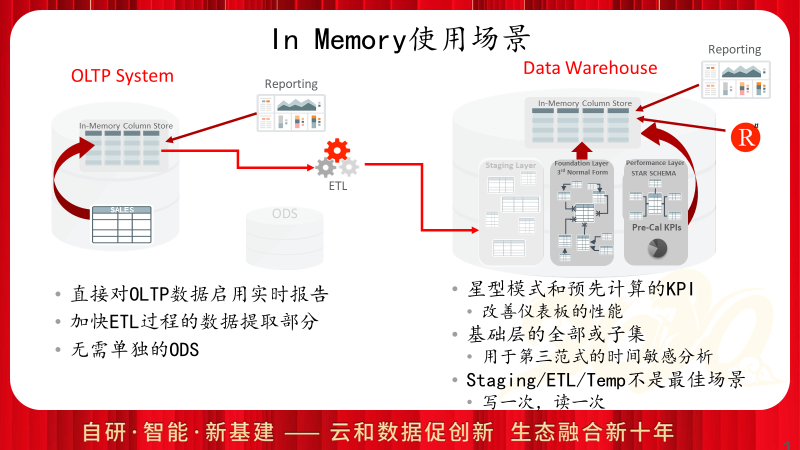
对于OLTP系统而言,In Memory带来的优势主要体现在ETL抽取过程,或在OLTP系统中运行一些实时报表的场景;而对于OLAP系统,In Memory对于数据集市和查询展现层都可以带来明显的性能提升,但是对于部署层由于其业务特点是写一次,读一次因此并不是最佳应用场景。

简单总结一下,如果是OLAP系统,那么是最佳应用场景,配合分区和In Memory压缩功能可以使得In Memory功能带来更好的使用效果,同时可以考虑开启自动建议功能;如果是纯OLTP系统,则不建议使用In Memory,其架构已经决定了对于DML没有性能提升,且还会存在少量的额外成本;而混合系统,可以考虑对于其中的报表查询对象开启In Memory功能,根据业务特点明确的选择候选表,可以在评估后删除一些纯报表查询使用的索引。

In Memory是独立的内存区域,开启In Memory功能需要为SGA和PGA中配置额外空间,需要注意调整临时空间的读写。另外,In Memory不支持纯OLTP的数据类型,比如索引组织表,HASH集群以及行外LOB等。

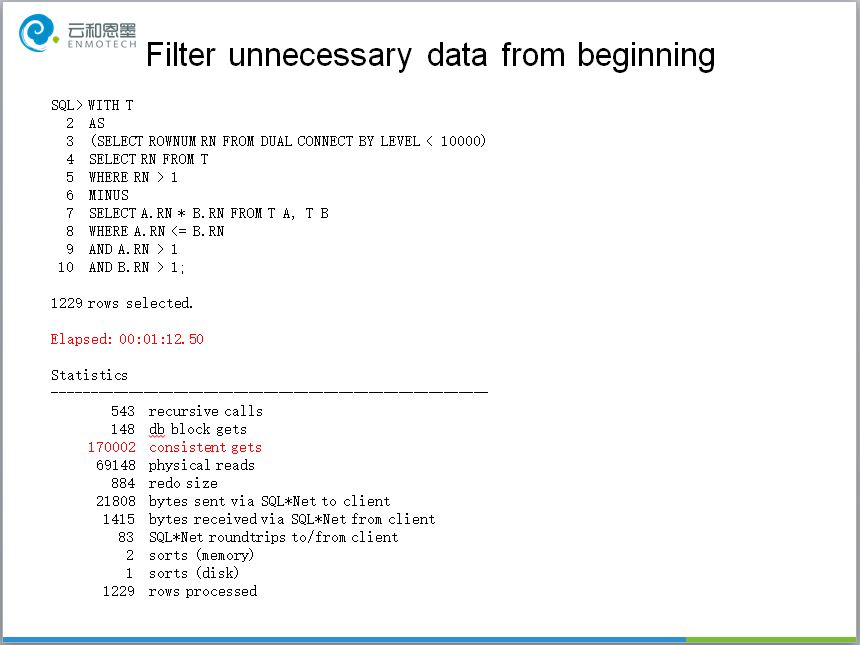
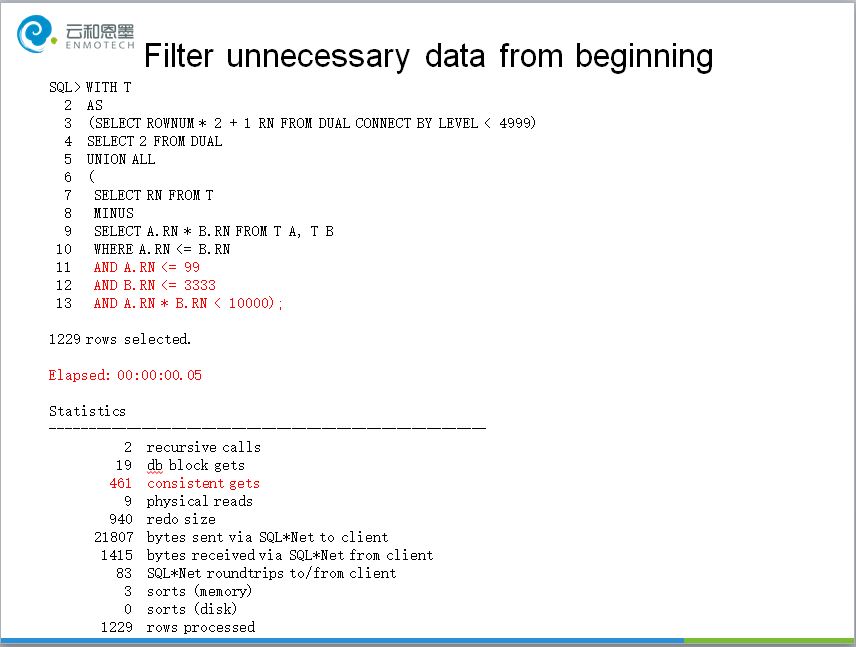
想要判断In Memory是否生效,对象是否加载到内存区域中,当前执行是否采用了In Memory扫描执行计划,并不是一件简单的工作。Oracle提供了一些列的视图和统计指标,其中V$INMEMORY_AREA和V$IM_SEGMENTS是常用视图,用来判断In Memory区域的分配状态,和对象加载状态。执行计划中的INMEMORY FULL信息并不代表当前对应的执行计划一定采用了In Memory扫描,而只是代表当前的配置允许In Memory执行计划发生,真正想要判断当前执行过的语句是否采用了In Memory,需要配合会话级统计IM scan rows的值。
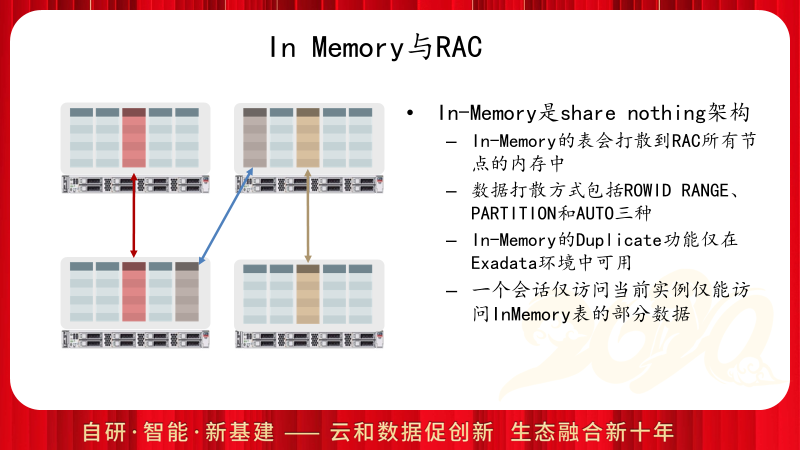
In Memory是OLAP的特性,因此采用了Share Nothing的架构,除了Exadata一体机外,普通的RAC配置下,表数据是打散到RAC所有节点上的,可以通过设置DISTRIBUTE语句指定数据打散方式。

由于RAC中表数据被打散到各个节点的内存中,如果想要在一个节点的查询访问到所有节点中的内存数据,必须开启并行查询。因此和In Memory功能直接相关的有两个初始化参数:PARALLEL_FORCE_LOCAL和PARALLEL_DEGREE_POLICY,前者必须设置为FALSE来启用跨节点并行,后者推荐设置为AUTO来启动自动并行访问,可以考虑通过手工会话级或语句级指定并行度的方式来代替全局的PARALLEL_DEGREE_POLICY参数设置。另外,可以配合DISTRIBUTE的SERVICE方式来配合业务的精细化In Memory的部署和访问。

In Memory是Oracle中的付费选件,而且In Memory使用的独立内存区域都是使用该功能的额外成本,需要关注In Memory对于一些非数据访问的功能是没有办法进行加速的。

上面介绍了从12c到19c,Oracle In Memory的一些功能和特性,下面我们看一下在20c/21c中,Oracle会带来哪些新的功能。

Oracle的In Memory功能仅需一个参数就可以实现全自动化的管理,不在需要管理员手工指定表的方式。内置的自动算法会根据表的访问频繁情况,自动决定加载表或从IN Memory内存中驱除表,还会自动对较少访问的数据进行压缩。
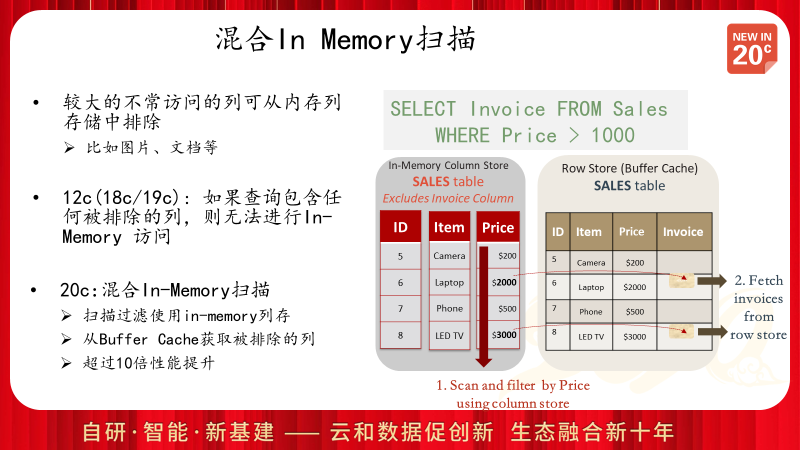
在12c的版本中,如果查询访问了In Memory设置中不包含的列,则该查询无法使用In Memory执行计划,而只能选择传统的DB Cache的访问方式,而最新的20c中,Oracle可以将列扫描和行扫描联合使用,从而更快的返回查询结果。
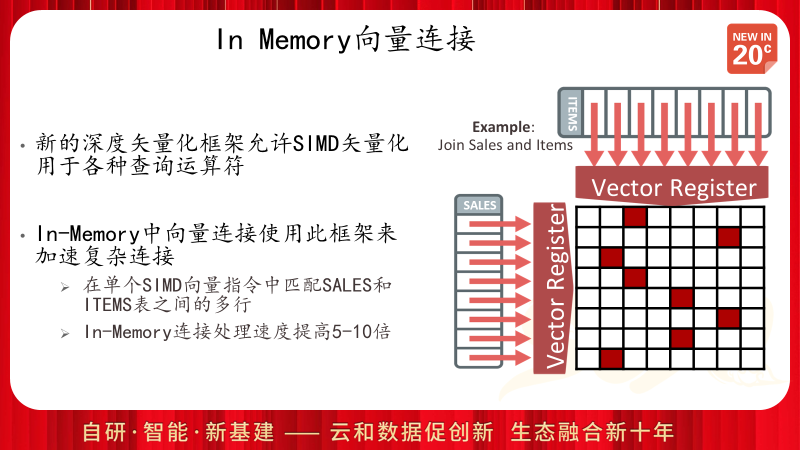
通过使用SIMD单指令多数据矢量处理模式,使得表连接的处理可以得到硬件级的加速,从而极大地提高连接处理效率。
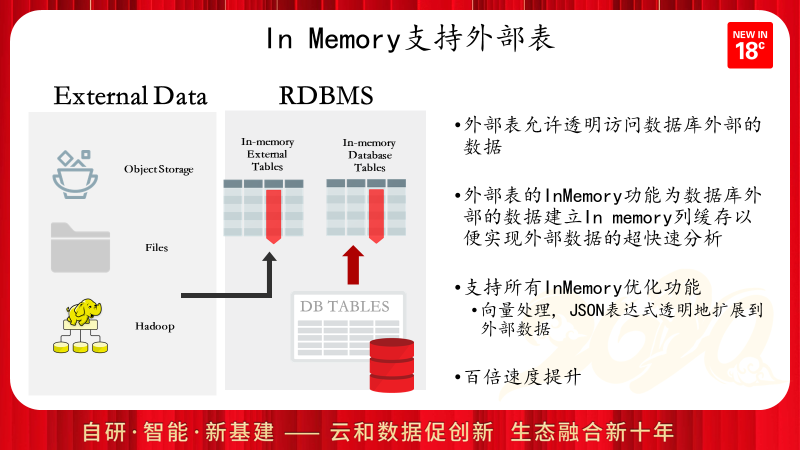
Oracle在18c中为外部表创建IN MEMORY缓存,从而极大的加快外部表数据的运算和分析过程,对于多次访问或进行复杂分析运算的外部表,启用IN MEMORY外部表功能,可能会得到成百倍的性能提升。
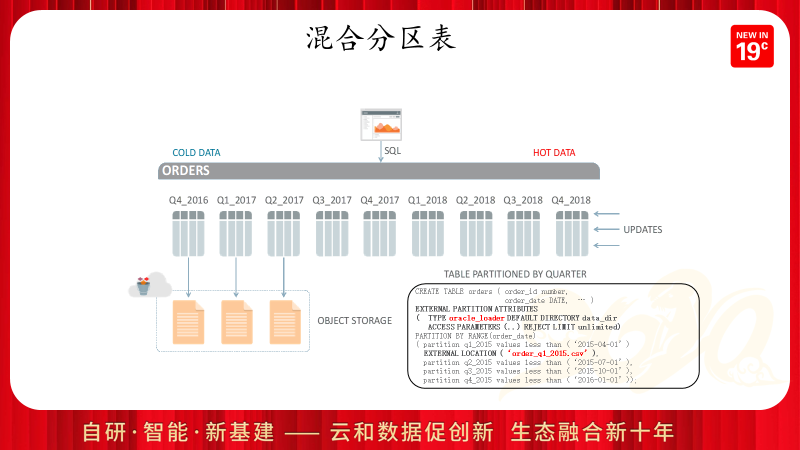
Oracle在19c中对于外部数据的混合存储功能进一步加强,允许分区表中部分分区为数据库内的在线数据,部分分区由存储在外部文件系统的外部数据构成。这使得数据库中全生命周期管理功能得到进一步完善。对于很少访问的历史数据,不需要通过额外的历史库或历史表去访问,而是通过原表不需要修改程序就可以直接访问到离线的只读数据。Oracle会对不同类型的分区进行分别处理,当一个SQL同时访问内部分区和外部分区时,Oracle将执行计划拆分为两个UNION ALL分支,采用不同的执行计划去获取数据。

而在最新的20c中,Oracle把In Memory在外部表和混合分区表上的功能进一步加强,In Memory支持外部表的基础上,对于混合分区表的表级别和分区级别都支持In Memory属性,而不管这个分区是内部的还是外部的。
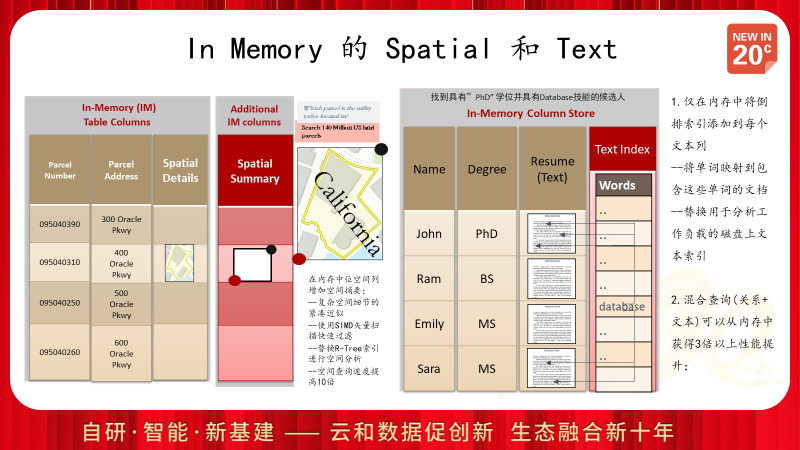
Oracle的In Memory功能不仅仅针对结构化数据,对于空间数据库和全文数据库,同样可以采用In Memory来进行加速,从而获得几倍或更高的性能提升。

最后简单总结一下In Memory的功能,对于OLAP系统而言,In Memory将带来复杂查询的巨大性能提升,对于DBA而言,合理的使用分区和并行,确保统计信息准确,可以保证In Memory功能得以更好的应用。但是对于纯OLTP系统而言,In Memory的开启还是会带来额外的负担,建议不要开启,或者在压力测试评估后谨慎使用。